
1. 목적
•
자기소개서에 적은 문구 "데이터의 정확도를 70% 이상 향상했습니다."에 대한 검증
•
Excel로 데이터 보정했던 방법을 Python으로 자동화
•
에너지 사용량 추세를 반영한 더 좋은 데이터 보정 방법 구현
2. 배경

데이터 보정 방법이 얼마나 정확하게 추세를 반영하는지 알고 싶다.
•
특정 구간의 보정한 값과 실제 값(가상 데이터) 오차율 계산
과거 데이터에서 더 많은 추세를 찾아 보정 결과의 정확도를 높이고 싶다.
데이터 보정 시 시간이 많이 소요되었던 부분을 개선하고 싶다.
대학교 건물의 에너지 관리 시스템 운영 업무 중에 에너지 사용량 데이터가 튀는 현상(이상치 발생)이 있었습니다. 특정 시점에서 데이터가 튀는 경우 다른 시간대 정상적인 데이터도 그래프 하단에 에너지 사용량이 없는 것처럼 나왔습니다.
정상적인 상태의 시스템 동작 과정은 센서가 에너지 사용량을 수집하면 일정 주기에 따라 데이터베이스에 데이터를 저장합니다. 이때 서버와 센서를 연결해 주는 프로그램(미들웨어)이 중간에서 0과 1로 되어있는 데이터를 받은 후 정보를 해석해서 DB에 전달해 주는 역할을 했습니다.
데이터가 튀는 문제는 센서가 정상적으로 값을 보내주지만, 중간에서 프로그램이 작동을 중지했다가 복구되는 경우 갑자기 큰 값이 들어오게 되면서 발생했습니다.
[정상 상태]
DateTime | 누적 값 | 사용량 |
2024-08-05 09:00 | 2,000 | 20 |
2024-08-05 09:15 | 2,020 | 20 |
2024-08-05 09:30 | 2,040 | 30 |
2024-08-05 09:45 | 2,070 | 30 |
2024-08-05 10:00 | 2,100 | 30 |
2024-08-05 10:15 | 2,130 | 35 |
2024-08-05 10:30 | 2,165 | - |
[비정상 상태(데이터가 튀는 현상)]
DateTime | 누적 값 | 사용량 |
2024-08-26 09:00 | 90,000 | 20 |
2024-08-26 09:15 | 90,020 | 0 |
2024-08-26 09:30 | 90,020 | 0 |
2024-08-26 09:45 | 90,020 | 0 |
2024-08-26 10:00 | 90,020 | 0 |
2024-08-26 10:15 | 90,020 | 200 |
2024-08-26 10:30 | 90,200 | - |
대학교 시설 관리자의 요청, 화면 모니터링 중 데이터가 튀는 현상을 발견 했습니다. 올바른 시간에 수집된 데이터지만 사용량 추세가 그래프에 표시되지 않았기 때문에 적절한 값으로 데이터를 보정해서 개발자에게 전달해야 했습니다.
이전 담당자는 문제가 발생한 시점과 복구된 시점의 누적값(적산 값) 차이를 구한 뒤 문제 발생 구간만큼 산술 평균을 구한 후 세부적으로 조정하고 반영했습니다. 이렇게 반영한 사용량 데이터는 과거 데이터의 추세를 반영하지 못하기 때문에 다른 방법을 찾아 적용했습니다.
데이터가 튀는 현상을 발견했을 때 제가 적용한 데이터 보정 순서는 아래와 같습니다.
1.
개발자에게 문제가 발생한 날의 건물별 누적값 데이터를 제공받습니다.
2.
문제 발생한 날이 포함된 주간과 비슷한 추세인 과거 주간 사용량 모니터링 그래프를 시스템에서 조회합니다.
3.
문제 발생한 날과 같은 요일의 에너지 사용량을 15분 단위로 다운로드하여 EXCEL에 정리합니다.
4.
수집한 데이터의 월 사용량으로 15분 단위 사용량을 나눠서 00:00부터 23:45까지 비율을 계산합니다.
5.
동일한 건물의 연 주차 별로 4번 결과 평균을 계산합니다.
6.
문제 발생 시점과 복구된 시점의 누적값 차이로 보정 필요한 값을 계산합니다.
7.
문제 발생 구간과 같은 시간대의 4번에 해당하는 값을 정리된 표에서 가져옵니다.
8.
6번에서 계산한 값에 5번에 해당하는 값을 적용해서 1차로 합계를 계산합니다.
9.
예상보다 8번 결과가 6번 결과보다 크거나 작을 수도 있어 절댓값을 문제가 발생한 구간의 개수로 나눠서 오차를 계산합니다.
10.
비교 결과 6번이 크면 오차만큼 더하고, 8번이 크면 오차만큼 빼줘서 8번과 6번을 동일하게 합니다.
11.
문제가 발생한 시점의 누적값에 보정한 사용량 데이터를 더해서 데이터 형식을 바꾼 후 개발자에게 문제 구간의 누적값을 전달합니다.
3. 결과
가상 데이터로 실험해 본 결과 이전에 데이터 보정에 사용했던 방법은 문제 발생 구간 값이 매우 크지 않는 경우 과거 데이터 추세를 반영하지 못한다.
월 사용량, 일 사용량 기반 비율 적용 시 값이 작아져 오차 증가
•
사용량 비율 계산 시 평균과 중앙값을 적용한 결과, MAE, MSE, 평균 오차율(Percentage Error) 간 큰 차이가 없음
◦
평균 적용 시 MAE : 5.10, MSE : 36.51, 평균 오차율 : 28.73%
◦
중앙값 적용 시 MAE : 5.14, MSE : 37.88, 평균 오차율 : 28.84%
•
오차 계산 시 절댓값에 특정 구간의 가중치를 적용한 값이 추세 반영에 효과적인 것으로 나타남
◦
유사도가 높은 과거 데이터에서 문제 구간과 동일한 구간의 가중치를 누적값 차이에 적용하는 방법을 적용
4. 데이터 설명
실제 데이터로 데이터 추세의 유사도를 확인하기에는 데이터 개수가 적고, 외부 공개할 수 없는 자료이기 때문에 Chat-GPT를 이용하여 가상으로 전력 사용량 데이터를 만들어서 데이터 보정 자동화에 활용하였습니다.
•
데이터 생성 기간 : 2024년 8월 1일부터 2024년 8월 31일까지
•
데이터 개수 : 2,976개(하루 96개 × 31일)
•
데이터 정보
컬럼명 | 설명 |
Date | AI가 생성해 준 날짜 , YYYY-MM-DD |
Time | AI가 생성해 준 15분 단위 시간, hh:mm:ss |
Usage | AI가 생성해 준 전력 사용량 |
DayOfWeek | AI가 생성 해 준 요일, 할루시네이션으로 삭제 |
weekday | Date 컬럼을 기준으로 다시 만든 요일 |
요일[ DayOfWeek] 컬럼이 할루시네이션으로 인해 토요일, 일요일 패턴이 월요일, 화요일 패턴으로 생성되었습니다. 프롬프트에 시작 일이 어떤 요일인지에 대한 정보를 추가로 주어야 할 것 같습니다.
하루 데이터 패턴에서 평균과 분산을 시간대에 따라 좀 더 세분화한다면 정교한 데이터 생성이 가능할 것 같습니다. 가능하다면 실제 건물 에너지 사용량 데이터를 구해서 문제 구간을 가정한 후 실험해 보는 것도 좋을 것 같습니다.
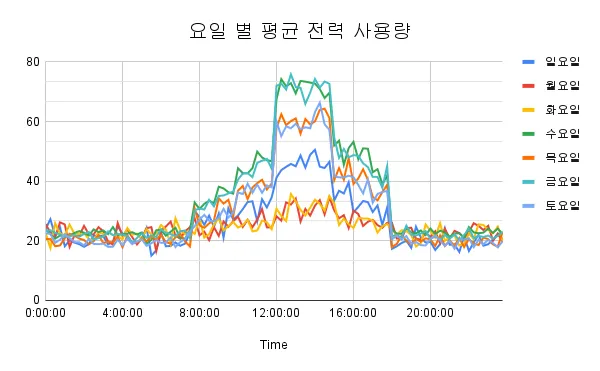
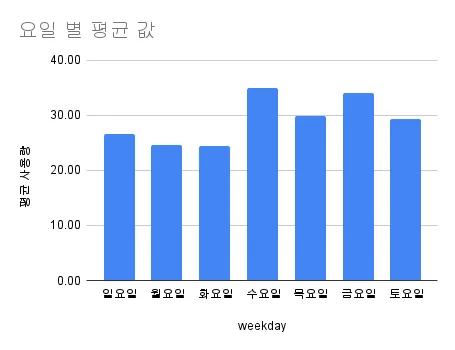
구 분 | 사용량 컬럼 |
개수 (count) | 2,976 |
평균 (mean) | 29.3 |
표준편차 (std) | 15.58 |
최솟값(min) | 3.89 |
최댓값(max) | 89.34 |
제 1사분위수 | 19.39 |
제 2사분위수 | 22.40 |
제 3사분위수 | 34.31 |
프롬프트
5. 근거
기존 데이터 보정 방법 구현
새로운 데이터 보정 방법 구현
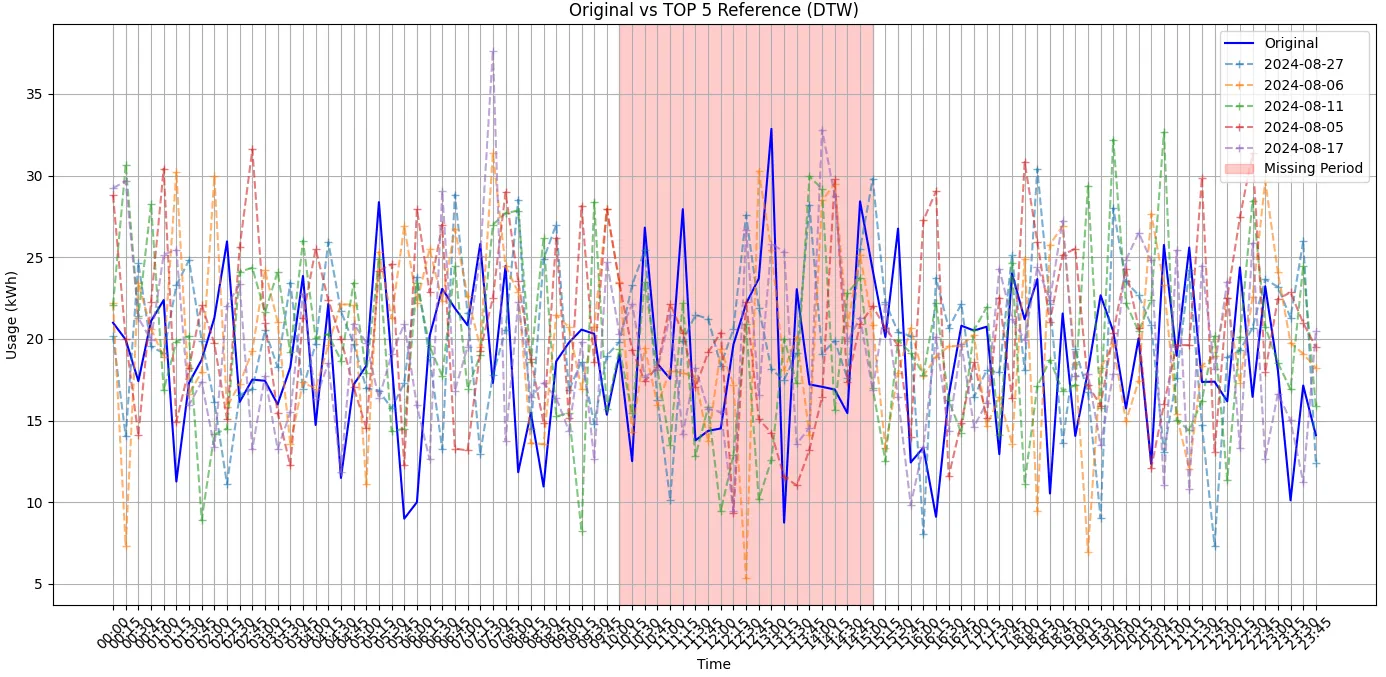
원본과 DTW 알고리즘으로 유사도가 높게 나온 시계열 데이터를 비교했을 때 데이터 추세가 닮아 보이진 않았습니다.
[원본 데이터와 유사성 높은 시계열 비교]
# 데이터 불러오기
data.loc[data['Date'] == '2024-08-26']
# datetime 형식 인덱스 생성
data['Datetime'] = data['Date'] + ' ' + data['Time']
data['Datetime'] = pd.to_datetime(data['Datetime'])
data.set_index('Datetime', inplace=True)
# data.head()
# 문제 구간 시간 정의 : 변수에 저장
missing_start = '2024-08-26 10:00:00'
missing_end = '2024-08-26 15:00:00'
# 문제 구간의 시간 정보를 리스트에 저장
time_missing = data.loc[missing_start: missing_end,'Time'].to_list()
time_missing
# 10:00:00 - 15:00:00
# 문제 구간의 인덱스 번호를 저장
time_missing_num = data.loc['2024-08-01 00:00:00' : '2024-08-01 23:45:00','Time'].reset_index()
time_missing_num = time_missing_num[time_missing_num['Time'].isin(time_missing) == True].index
time_missing_num = list(time_missing_num)
time_missing_num
# 40 - 60
# 10시부터 15시 데이터 합계변수에 저장
missing_sum = data.loc[missing_start : missing_end,'Usage'].sum()
missing_sum
# 414.4869221786749
# 문제 발생 현상 가정 : 해당 구간 삭제, NULL 처리, 보간법 이용
# 해당 구간의 데이터를 삭제한 경우
day_usage_missing = data.loc[data['Date'] == '2024-08-26', 'Usage'].drop(data.loc[missing_start : missing_end,].index)
# 데이터가 Null인 경우 : 유사도 계산 시 거리 NULL 출력
# day_usage_missing = data.loc[data['Date'] == '2024-08-26', 'Usage']
# day_usage_missing.loc[missing_start : missing_end] = np.nan
# 해당 구간에 선형 보간을 한 경우 : 선형보간. 시계열 보간, 다항보간을 시도함
# 선형보간과 시계열 보간은 차이가 없었고, 다항 보간 결과는 음수가 발생되었다.
# day_usage_missing = data.loc[data['Date'] == '2024-08-26', 'Usage']
# day_usage_missing.loc[missing_start : missing_end] = np.nan
# day_usage_missing = day_usage_missing.interpolate(method='polynomial', order = 3)
# day_usage_missing.info()
# day_usage_missing.loc[missing_start : missing_end]
# 전체 과거 데이터를 리스트 형식으로 저장
reference_series_list = []
for day in data['Date'].unique():
# 문제 구간의 날짜와 같은 경우 리스트에서 제외
if day == '2024-08-26':
continue
# 날짜 기준으로 데이터 필터링
day_data = data[data['Date'] == day]
# 같은 날짜의 사용량 필터링
day_usage_no_missing = day_data['Usage']
# 리스트에 저장
reference_series_list.append(day_usage_no_missing)
# 참조 데이터 배열 구조 확인
reference_series_array = np.array(reference_series_list)
reference_series_array.shape
# (30, 96)
# 문제 구간 데이터 배열 구조 확인
np.array(day_usage_missing.values).shape
# (75, )
# dtw 패키지 설치
!pip install dtaidistance
# dtw 알고리즘 불러오기
from dtaidistance import dtw
# DTW를 사용하여 가장 유사한 상위 5개 구간 찾기
top_n = 5
# 데이터 유사도 계산 함수 정의
def find_top_n_similar_patterns_dtaidistance(target_series, reference_series_list, top_n):
distances = []
for ref_series in reference_series_list:
# 1차원 배열로 변환
ref_series_values = np.array(ref_series).flatten()
# 참조 데이터 날짜 구하기
day = ref_series.index[0].date()
# print(day)
# DTW 거리 계산
distance = dtw.distance(target_series, ref_series_values)
distances.append((day, ref_series_values, distance))
# 거리가 가장 작은 N개의 패턴 선택
distances.sort(key=lambda x: x[2]) # 거리 기준으로 정렬
top_n_patterns = [dist[1] for dist in distances[:top_n]] # 상위 N개 패턴 추출
top_n_day = [dist[0] for dist in distances[:top_n]] # 참조 데이터 날짜 추출
return top_n_day, top_n_patterns, distances[:top_n]
# 유사한 상위 N개 구간 찾기
target_series_values = np.array(day_usage_missing.values).flatten()
top_n_day, top_n_patterns, top_n_distances = find_top_n_similar_patterns_dtaidistance(target_series_values, reference_series_list, top_n)
# 유사도가 높은 시계열 합계
day_sum = []
for i in range(len(top_n_patterns)):
day_sum.append(top_n_patterns[i].sum())
day_sum
# 1903.8395197691166,1913.170950312985, 1885.736269642547, 1954.4214128181347, 1856.0490721363353
# 데이터 복사
top_n_patterns_origin =top_n_patterns.copy()
# 15분 단위 사용량 비율 구하기
for i in range(len(top_n_patterns)):
top_n_patterns[i] = top_n_patterns[i]/day_sum[i]
top_n_patterns, top_n_patterns_origin
# 15분 단위 사용량 평균 및 중앙값 비율 계산
dtw_average_pattern = np.mean(top_n_patterns, axis=0)
dtw_median_pattern = np.median(top_n_patterns, axis=0)
dtw_average_pattern, dtw_median_pattern
# 평균 비율을 이용한 보정값 계산
mean_corrected_values = dtw_average_pattern[time_missing_num[0]:time_missing_num[-1]+1] * missing_sum
# 중앙값 비율을 이용한 보정값 계산
median_corrected_values = dtw_median_pattern[time_missing_num[0]:time_missing_num[-1]+1] * missing_sum
mean_corrected_values, median_corrected_values
# 문제 구간의 합계와 보정 값 차이 구하기
# 평균
diff_mean = abs(missing_sum - mean_corrected_values.sum())
# 중앙값
diff_median = abs(missing_sum - median_corrected_values.sum())
diff_mean, diff_median
# 325.8081189208989, 325.3765464309829
# 특정 구간 가중치 구하기
# 유사도가 높은 구간 평균
top_n_patterns_mean = np.mean(top_n_patterns_origin, axis =0)
# 특정 구간 10:00~ 15:00 합계
sum_10to15 = top_n_patterns_mean[time_missing_num[0]:time_missing_num[-1]+1].sum()
# 가중치
sum_10to15_ratio = top_n_patterns_mean[time_missing_num[0]:time_missing_num[-1]+1] / sum_10to15
sum_10to15_ratio
# 문제 구간의 합계와 보정 값 차이에 가중치 반영해주기
diff_mean_10to15 = sum_10to15_ratio * diff_mean
diff_median_10to15 = sum_10to15_ratio * diff_median
diff_mean_10to15, diff_median_10to15
# 시각화 및 오차율 계산을 위한 데이터
# 원본 값 추가
day26data = data.loc['2024-08-26 00:00:00':'2024-08-26 23:45:00','Usage'].reset_index()
# 평균 보정값 컬럼 생성 후 원본 값 추가
day26data.loc[:, 'Mean_corrected'] = day26data['Usage']
# 중앙값 이용 보정값 컬럼 생성 후 원본 값 추가
day26data.loc[:, 'Median_corrected'] = day26data['Usage']
day26data.set_index('Datetime', inplace=True)
# 문제 구간에 평균값, 중앙값 이용 보정 결과 추가
day26data.loc['2024-08-26 10:00:00' : '2024-08-26 15:00:00', 'Mean_corrected'] = mean_corrected_values + diff_mean_10to15
day26data.loc['2024-08-26 10:00:00' : '2024-08-26 15:00:00', 'Median_corrected'] = median_corrected_values + diff_median_10to15
day26data.loc['2024-08-26 09:00:00' : '2024-08-26 16:00:00',]
# 평균 기반 보정값의 오차 계산
day26data['Mean_Error'] = day26data['Usage'] - day26data['Mean_corrected']
day26data['Mean_Absolute_Error'] = abs(day26data['Mean_Error'])
day26data['Mean_Percentage_Error'] = (day26data['Mean_Absolute_Error'] / day26data['Usage']) * 100
# 중앙값 기반 보정값의 오차 계산
day26data['Median_Error'] = day26data['Usage'] - day26data['Median_corrected']
day26data['Median_Absolute_Error'] = abs(day26data['Median_Error'])
day26data['Median_Percentage_Error'] = (day26data['Median_Absolute_Error'] / day26data['Usage']) * 100
# 평균 오차율, MAE, MSE 계산
mean_mae = day26data.loc[missing_start:missing_end, 'Mean_Absolute_Error'].mean()
mean_mse = (day26data.loc[missing_start:missing_end, 'Mean_Absolute_Error'] ** 2).mean()
mean_percentage_error = day26data.loc[missing_start:missing_end, 'Mean_Percentage_Error'].mean()
median_mae = day26data.loc[missing_start:missing_end, 'Median_Absolute_Error'].mean()
median_mse = (day26data.loc[missing_start:missing_end, 'Median_Absolute_Error'] ** 2).mean()
median_percentage_error = day26data.loc[missing_start:missing_end, 'Median_Percentage_Error'].mean()
# 오차율 계산 결과
(mean_mae, mean_mse, mean_percentage_error), (median_mae, median_mse, median_percentage_error)
# (5.103125426633748, 36.509329674711395, 28.727154797337146), (5.135126110188547, 37.882991916545784, 28.837145599275107)
# 원본 데이터, 평균 기반 보정값, 중앙값 기반 보정값 시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 7))
plt.plot(day26data.index, day26data['Usage'], label='Original', color='green')
plt.plot(day26data.index, day26data['Mean_corrected'], label='Mean Corrected Usage', linestyle='--', color='blue')
plt.plot(day26data.index, day26data['Median_corrected'], label='Median Corrected Usage', linestyle='dashdot', color='orange')
plt.axvspan(missing_start, missing_end, color='red', alpha=0.1, label='Missing Period')
plt.title('Original vs Mean Corrected vs Median Corrected Usage')
plt.xlabel('Time')
plt.ylabel('Usage (kWh)')
plt.xticks(rotation=45)
plt.legend()
plt.grid()
plt.show()
# DTW 유사도 측정 결과 시각화
import matplotlib.pyplot as plt
# 00:00부터 23:45까지의 시간 인덱스 생성
time_index = pd.date_range(start='00:00', end='23:45', freq='15T').strftime('%H:%M')
# 대상 시계열 데이터
target_series_values = np.array(day26data['Usage'].values).flatten()
# DTW로 찾은 상위 5개의 시계열 패턴
top_n_patterns_values = [np.array(pattern).flatten() for pattern in top_n_patterns_origin]
# 시각화
plt.figure(figsize=(14, 7))
# 대상 시계열 데이터 시각화
plt.plot(time_index, target_series_values, label='Original', color='blue')
# 상위 N개의 참조 시계열 데이터 시각화
for i, pattern in enumerate(top_n_patterns_values):
plt.plot(time_index, pattern, linestyle='--',marker = '+', label= top_n_day[i], alpha=0.6)
# 누락된 구간 강조 (대상 데이터의 누락 구간을 음영 처리)
plt.axvspan('10:00', '15:00', color='red', alpha=0.2, label='Missing Period')
# 그래프 설정
plt.title('Original vs TOP 5 Reference (DTW)')
plt.xlabel('Time')
plt.ylabel('Usage (kWh)')
plt.xticks(rotation=45)
plt.legend()
plt.grid(True)
plt.tight_layout()
# 그래프 출력
plt.show()
Python
복사
